

Der virtuelle Berater: Generative AI & LLM als nächster Schritt im Omnichannel

Senacor
Spätestens seit ChatGPT sind Generative AI und Large Language Models (LLM) im Mainstream angekommen. Ein Use Case für den Bereich Retail Banking könnte ein virtueller Berater sein. Ein solches System ist der logische nächste Schritt in einer Omnichannel-Strategie: Eine Bank wird kanalübergreifend zu jeder Uhrzeit für ihre Kunden ansprechbar.
von Dr. Richard Müller, Managing Consultant Banken und Finanzdienstleister, Senacor
Alle Retail-Banken sind auf der Suche nach der perfekten Omnichannel-Lösung. Die Nutzung eines Large Language Models (LLM) zur Implementierung eines virtuellen Beraters ist hierbei aus verschiedenen Gründen interessant. “Einfache” Aufgaben wie das Abrufen von Produktinformationen oder niedrigschwellige Bestellprozesse könnten vom virtuellen Berater übernommen werden.Das LLM hat also Potenzial, Personalkosten zu sparen.”
Die ständige örtliche und zeitliche Verfügbarkeit des virtuellen Beraters macht die Interaktion mit der Bank komfortabler und verbessert so das Kundenerlebnis.
Gleichzeitig sind auch Verkäufe oder Abschlüsse immer möglich, was sich positiv auf die Rendite auswirkt. Eine Fokussierung der menschlichen Berater auf komplexe Aufgaben steigert deren Beratungsqualität zusätzlich.
Senacor
Um die aktuellen Entwicklungen und Möglichkeiten rund um Large Language Models (LLM) im Banking zu verstehen, lohnt sich die intensive Analyse dieses Use Cases.
Der virtuelle Berater – Ein Konzeptvorschlag
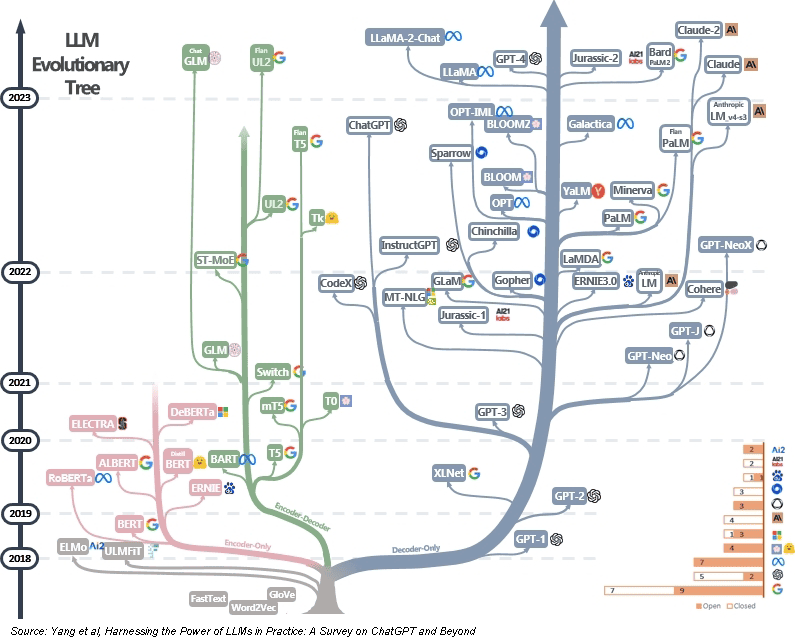
Wer einen virtuellen Berater in die eigene IT-Landschaft implementieren will, muss zunächst entscheiden, auf welchem LLM das Ganze basieren soll. Neben ChatGPT existieren andere, ähnlich performante Modelle.”
Wer einen virtuellen Berater in die eigene IT-Landschaft implementieren will, muss zunächst entscheiden, auf welchem LLM das Ganze basieren soll. Neben ChatGPT existieren andere, ähnlich performante Modelle.”
Aktuell werden jeden Monat neue LLM angekündigt oder vorgestellt, sowohl Closed als auch Open Source. Des weiteren gilt es zu klären, wie viele Ressourcen für ein solches Projekt zur Verfügung stehen. Ein komplett eigenes LLM zu entwerfen, ist in den meisten Fällen überflüssig. Denn die benötigte Rechenleistung wird durch vortrainierte LLM (“Foundation Models”) um bis zu 98 % reduziert. Das spart Kosten und Ressourcen.
Für einen Großteil der Anwendungen eigenen sich diese Foundation Models (FM). Bereits existieren diverse performante FM als Closed oder auch Open Source. Dazu zählen Llama 2 von Meta, Falcon von TII oder MPT von Mosaic. Das Vortraining reicht allerdings nicht aus, um diese Modelle als kompetente Berater zu nutzen. Es muss eine weitere Trainingsphase folgen – das Finetuning. Dabei wird das Modell auf den konkreten Use Case (z.B. Chat mit Menschen) spezialisiert. Open-Source-Dialogmodelle wie Alpaca, Vicuna oder Koala haben gezeigt, dass die Kosten für Finetuning massiv gesenkt werden können. So ist ein Finetuning schon für 100 Dollar möglich. In der Theorie ist es dabei machbar, eine ähnliche Performance wie ChatGPT zu erreichen. In der Praxis basiert der Erfolg der Dialogmodelle aber vor allem auf der Verwendung qualitativ hochwertiger, vielfältiger Daten echter Nutzer.
Senacor
Zu wenig Daten für zu viel LLM
Die Performance des LLM skaliert nicht nur mit der Masse seiner Trainingsdaten, sondern ebenso mit deren Qualität. Bessere Daten bedeuten mehr Leistungsfähigkeit. Gleichzeitig wächst die Menge benötigter Trainingsdaten für LLM unaufhörlich. Die Menge der genutzten Daten wird in Token gemessen. Ein englisches Wort entspricht dabei ca. 0,75 Token. Das Trainingsset von OpenAIs GPT-3 umfasst 0,5 Billionen Token (2020), das von Googles PaLM 2 (2023) schon 3,6 Billionen. Zur Einordnung: Nach einer Schätzung von Google Books 2010 existieren 130 Millionen unterschiedliche einzigartige Bücher auf der Erde. Alle zusammen ergeben ca. 8,66 Billionen Token.
Die Menge der benötigten Tokens ist eine Herausforderung. Es ist unklar, ob genügend hochwertige Daten existieren, mit denen immer größere LLM trainiert werden können. Dies hat unterschiedliche Gründe. Ein Teil der Trainingsdaten stammt von Plattformen wie Reddit und Stack Overflow. Beide haben inzwischen ihre AGBs geändert und den Zugang erschwert. Andere Daten sind schwierig zu erreichen, zum Beispiel Daten des chinesischen Internets hinter der Great Firewall. Wieder andere im Internet veröffentlichte Daten sind nicht nutzbar, da sie vom Urheberrecht geschützt sind oder selbst von einem LLM stammen.
Spezialisierung der Beratungskompetenz
Autor Dr. Richard Müller, Senacor Dr. Richard Müller ist Managing Consultant Banken und Finanzdienstleister bei Senacor (Website). Seine Expertise erstreckt sich über die Gebiete Solution Architecture, Product Ownership und den Einsatz von Künstlicher Intelligenz. Neben dem Informatik- und BWL-Studium arbeitete er mehrere Jahre als Softwareentwickler, bevor er in Berlin und Eindhoven in theoretischer Informatik und Process Mining promovierte. Seine Erfahrung und sein Fachwissen hat er u.a. in den Aufbau einer Practice zu Smart Data & AI bei Senacor eingebracht.
Dr. Richard Müller ist Managing Consultant Banken und Finanzdienstleister bei Senacor (Website). Seine Expertise erstreckt sich über die Gebiete Solution Architecture, Product Ownership und den Einsatz von Künstlicher Intelligenz. Neben dem Informatik- und BWL-Studium arbeitete er mehrere Jahre als Softwareentwickler, bevor er in Berlin und Eindhoven in theoretischer Informatik und Process Mining promovierte. Seine Erfahrung und sein Fachwissen hat er u.a. in den Aufbau einer Practice zu Smart Data & AI bei Senacor eingebracht.
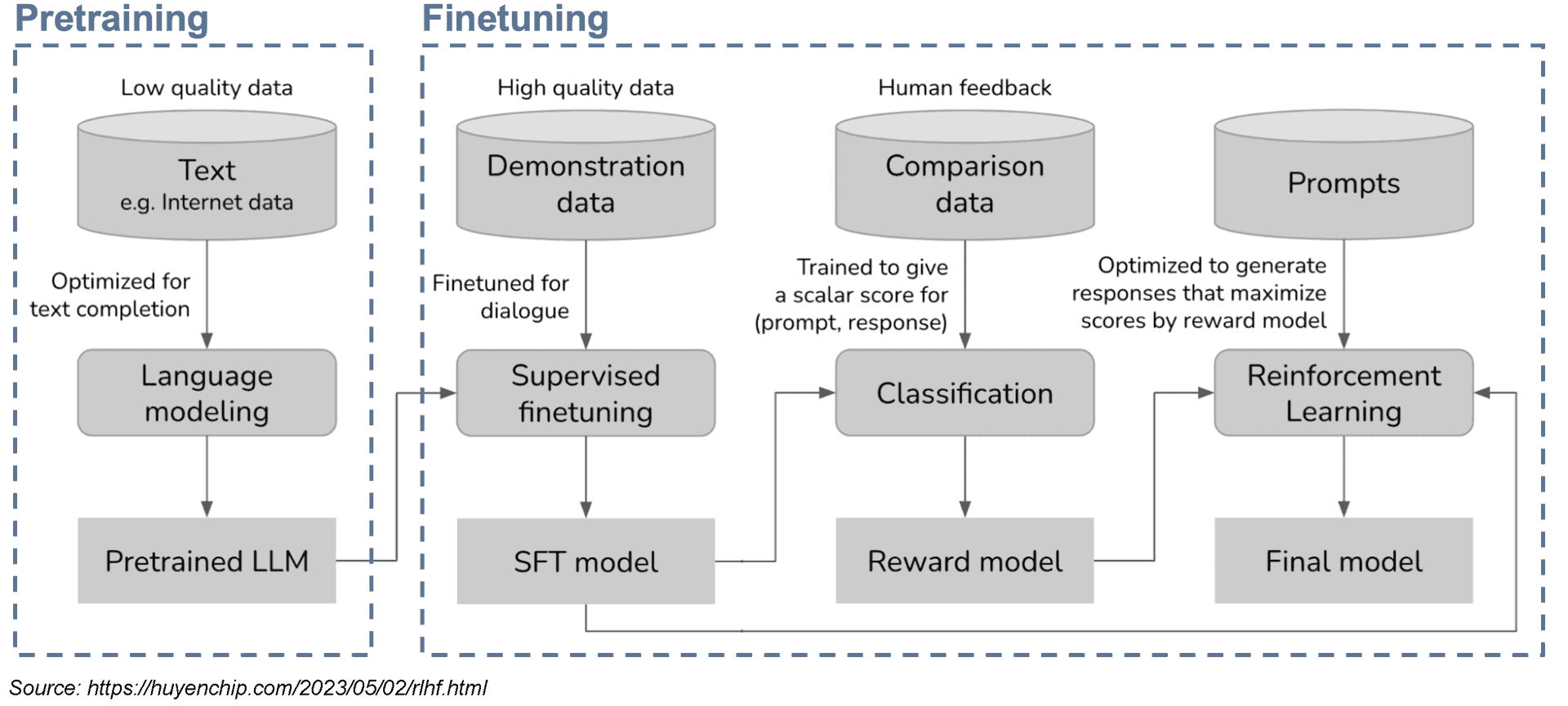
Zur Kernkompetenz eines virtuellen Beraters gehört, dass dieser kundenspezifisch beraten kann. Prinzipiell können Kundendaten zur Build-Time oder zur Run-Time ins LLM kommen.”
Dr. Richard Müller ist Managing Consultant Banken und Finanzdienstleister bei Senacor (Website). Seine Expertise erstreckt sich über die Gebiete Solution Architecture, Product Ownership und den Einsatz von Künstlicher Intelligenz. Neben dem Informatik- und BWL-Studium arbeitete er mehrere Jahre als Softwareentwickler, bevor er in Berlin und Eindhoven in theoretischer Informatik und Process Mining promovierte. Seine Erfahrung und sein Fachwissen hat er u.a. in den Aufbau einer Practice zu Smart Data & AI bei Senacor eingebracht.Zur Kernkompetenz eines virtuellen Beraters gehört, dass dieser kundenspezifisch beraten kann. Prinzipiell können Kundendaten zur Build-Time oder zur Run-Time ins LLM kommen.”
Bei ersterer werden die Daten genutzt, um das System zu trainieren (Training und Finetuning), bei letzterer, um damit Text zu generieren (Inferenz). Ein speziell auf eine Retail Bank zugeschnittener Berater könnte folgende Daten nutzen: Öffentliche Daten von Websites der Bank oder aus Geschäftsberichten. Nicht öffentliche Daten zu Produkten und Prozessen sowie Kundendaten in Form von Stammdaten, Transaktionsdaten oder Inventardaten. Viele dieser Daten ändern sich ständig. Aus diesem Grund sollten sie zur Run-Time ins LLM kommen, um ein Re-Training bei jeder Datenänderung zu vermeiden.
Die Eingabe in ein LLM zur Run-Time wird Prompt genannt. In diesem Beispiel umfasst ein Prompt mindestens eine Verhaltensbeschreibung des virtuellen Beraters, eine Beschreibung der Aufgabe, die vom LLM erledigt werden soll (z.B. eine Frage des Kunden beantworten) sowie eine Beschreibung des relevanten Kontexts zur Aufgabe (z.B. Stamm- und Transaktionsdaten des Kunden). Prompt Engineering beziehungsweise die Entwicklung und Ausformulierung dieser Beschreibungen ist noch nicht ausgereift.
Aktuell fehlt der Forschung das präzise Verständnis dafür, warum manche Prompts funktionieren und andere nicht. Mit der Klärung dieser Frage beschäftigt sich u.a. das Forschungsfeld der “Explainable AI”.”
Um einen passenden Prompt zu formulieren, werden unterschiedliche Datentöpfe angesprochen. Kundenunspezifische Daten werden mittels semantischer Suche aus Datenbanken geholt und in den Kontext des Prompts aufgenommen. Kundenspezifische Daten hingegen können über passende APIs geholt werden. Diese APIs müssen zur Verfügung stehen. Dies gilt umso mehr, wenn der virtuelle Berater später Aktionen zum Beispiel einen Produktabschluss im Namen eines Kunden ausführen soll. Eine praktikable Implementierung des virtuellen Beraters ist also nur dann möglich, wenn Daten und Prozesse der Bank im Vorfeld sinnvoll digitalisiert worden sind.
Digitalisierung als vorbereitende Maßnahme wird wichtiger, da Prompts komplexer werden. GPT-3 erlaubt pro Prompt bis zu 2.000 Tokens. Dies entspricht ungefähr drei DIN-A4-Seiten. Ein MPT-Modell von Mosaic hingegen erlaubt bis zu 65.000 Tokens pro Prompt, einer Menge von 100 DIN-A4-Seiten. Ein längerer Prompt bedeutet, dem Modell mehr Informationen, mehr Kontext, mehr Beispiele zur Run-Time übergeben zu können, ohne das Modell selbst zu verändern. Prompts werden, wenn richtig formuliert, damit genauer und besser.
Ein Ausblick
Für Prompts zeichnen sich folgende Entwicklungen ab. Sie sind wichtig, aber unzureichend verstanden. Sie werden länger und machen den virtuellen Berater so kompetenter. Dafür muss vorher sinnvoll digitalisiert worden sein.
Für LLM liegt der Fokus der Entwicklungen vor allem auf der Qualität der generierten Texte.”
LLM können momentan keine absolute Qualität garantieren. Sie erzeugen kontextualisierte Texte, die kohärent, aber nicht unbedingt sachlich korrekt sind. Ihre Trainingsdaten und damit das Weltwissen des virtuellen Beraters ist beschränkt. Ereignisse, die nach Abschluss seines Trainings stattfanden, kann er in Antworten nicht berücksichtigen. Seine Antworten können vorurteilsbehaftet sein, da seine Trainingsdaten nicht vorurteilsfrei sind.
Zur Minderung dieser Limitierungen können verschiedene Maßnahmen kombiniert werden. So können “Standardfragen” ohne Mitwirkung des LLMs beantwortet werden. Ein Beispiel dafür wäre die Frage “Wie hoch ist mein Kontostand?”, welche der virtuelle Berater mittels API-Zugriff und Standardformulierung beantwortet. Neue Prompt-Techniken wie “System Messages” erlauben mehr Kontrolle über die Ausgabe des LLM. Durch die Kontrolle der Trainingsdaten beim Finetuning kann ein vorurteilsfreieres LLM ausgewählt werden. Und Mithilfe einer Vielzahl von Quality Gates kann die Qualität der Antworten weiter verbessert werden. Diese reichen von einfachen Blacklists oder Stichwortprüfungen bis hin zu separaten Modellen, welche Ton, Relevanz oder Angemessenheit der erzeugten Antwort bewerten, bevor diese an den Kunden ausgespielt wird.Dr. Richard Müller, Senacor
Sie finden diesen Artikel im Internet auf der Website:
https://itfm.link/160683


Schreiben Sie einen Kommentar