
Der aktuelle Entwicklungsstand von Tools zur Daten-Anonymisierung

Aircloak
Daten-Anonymisierung hat im Kontext der DSGVO erneut an Aufmerksamkeit gewonnen – ist aber nicht immer einfach umzusetzen. Sebastian Probst Eide, CTO des deutschen Startups Aircloak, erläutert, wo die aktuellen Herausforderungen liegen.
von Sebastian Probst Eide, CTO Aircloak
Anonymisierte Daten sind von der DSGVO (Datenschutzgrundverordnung seit 25. Mai 2018 europaweit in Kraft) nicht betroffen. Dort heißt es im Erwägungsgrund 26:Die Grundsätze des Datenschutzes sollten daher nicht für anonyme Informationen gelten, d.h. für Informationen, die sich nicht auf eine identifizierte oder identifizierbare natürliche Person beziehen, oder personenbezogene Daten, die in einer Weise anonymisiert worden sind, dass die betroffene Person nicht oder nicht mehr identifiziert werden kann.”
Dieser kurze aber sehr wichtige Zusatz zur Grundverordnung stellt klar heraus, dass es gesetzeskonforme Optionen im alltäglichen Umgang mit sensiblen Daten gibt. Grund genug, sich näher mit diesem Fall auseinanderzusetzen, wenn Sie mithilfe von Anonymisierung das volle Potenzial Ihrer Daten nutzen wollen.
Wenn nun der Datensatz die Dimensionen Alter und Geschlecht wie in der folgenden Tabelle enthält…
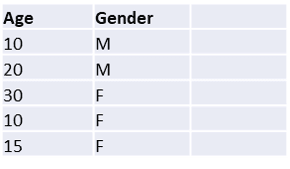
…dann könnte man ihn anonymisieren, indem man das Alter verallgemeinert. Das Ergebnis würde dann so aussehen:
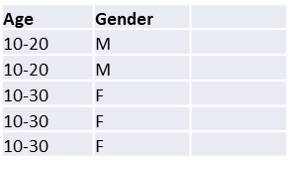
Fügen wir nun eine weitere Kategorie hinzu, nämlich die Automarke, die der- oder diejenige besitzt:
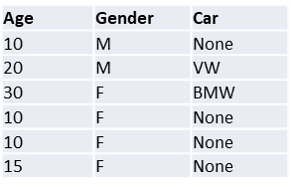
Um diesen umfangreicheren Datenbestand zu anonymisieren, müssen die Daten noch weiter verallgemeinert werden. Dafür gibt es verschiedene Möglichkeiten, aber ein Beispiel wäre:

Je mehr Dimensionen hinzugefügt werden, desto mehr Informationen müssen anonymisiert werden. Dadurch verschlechtern sich die analytischen Möglichkeiten, die ein Datensatz, der mit klassischen Methoden anonymisiert wurde, bietet. Moderne Anonymisierungslösungen wie Differential Privacy oder Diffix können diesem Problem entgegenwirken.
Data Masking, Pseudonymisierung und Anonymisierung
Kaum einer kennt die Unterschiede zwischen Data Masking, Pseudonymisierung und Anonymisierung. Data Masking und Pseudonymisierung unterscheiden sich von Anonymisierung dadurch, dass Daten immer noch Identifikationsmerkmale enthalten, die (zumindest durch “Herziehung zusätzlicher Informationen”, wie die DSGVO ausführt) eine Zuordnung zu einer Person möglich machen – bei korrekt anonymisierten Daten wäre das nicht mehr der Fall. Aber dieses Wissen bringt uns allein noch nicht weiter, wenn wir mit einem sensiblen Datensatz arbeiten möchten oder für andere freigeben wollen.
Ansätze für Anonymisierung funktionieren nicht immer
Natürlich gibt es bereits etablierte Ansätze für Anonymisierung. Diese setzen allerdings voraus, dass sie die Dimensionen (Spalten) in Ihrem Datenbestand als identifizierend oder nicht-identifizierend kategorisieren können. Auf diese Weise erkennt ein Algorithmus, welche Informationen zu bearbeiten sind. Für einige Daten ist das noch relativ einfach umzusetzen. Kombinationen wie Vor- und Nachnamen sind meist eindeutig identifizierende Merkmale, ebenso wie Sozialversicherungs- oder Kontonummer einer Person. In anderen Fällen wird die Zuordnung komplizierter:
Ist die Zeit, wann jemand morgens sein Haus verlässt oder die Farbe seines Pullovers identifizierend? In der Regel hängt es davon ab, über welches zusätzliche Wissen die Person verfügt, die Zugriff auf den Datensatz erhält.”
In der Praxis führt das zuweilen zu haarsträubenden Ergebnissen. So wurde im Jahr 2002 in den USA eine medizinische Datenbank anonymisiert und veröffentlicht. Durch die Kombination des medizinischen Datensatzes mit einem öffentlich zugänglichen Wahlregister hatte die Forscherin Latanya Sweeney Zugriff auf die vollständige Krankenakte des Senators von Massachusetts!
Ist Datenschutz mit einer hohen Datenqualität vereinbar?
Das eigentliche Problem liegt darin, dass man nie genau vorhersagen kann, welche andere Quellen außerhalb des ursprünglichen Datensatzes noch zur Verfügung stehen könnten. Das führt uns zu der eher pessimistischen Ansicht, dass jede Dimension potenziell identifizierend sein kann und daher auch wie eine solche behandelt werden muss. Bei einem Lösungsansatz durch einer der derzeitigen Standard-Anonymisierungstechniken wie K-anonymity oder L-diversity leidet die Datenqualität jedoch dramatisch.
Je umfangreicher der Datensatz ist (also je mehr Dimensionen er enthält), desto schlechter wird das Ergebnis in Bezug auf seine Aussagefähigkeit. Wegen dieser Herausforderungen haben sich die meisten Analysten von der Idee der Anonymisierung verabschiedet.”
Bei der Datenverwertung hatte man in der Vergangenheit oft nur die Wahl zwischen einem unzureichend anonymisierten Datensatz und Daten ohne Aussagekraft. Die beste Option mag dann sein, stattdessen gänzlich auf die Auswertung zu verzichten.
 Sebastian Probst Eide ist CTO und Mitgründer von Aircloak. Nach seinem Informatikstudium an der Universität Cambridge arbeitete er mit Paul Francis, Direktor vom Max-Planck-Institut für Softwaresysteme und Felix Bauer an der Entwicklung von neuen Anonymisierungskonzepten. 2014 gründeten sie gemeinsam das Startup Aircloak. Mit der Lösung Aircloak Insights, die auf der neu entwickelten Anonymisierungsmethode Diffix basiert, möchten sie Unternehmen aussagekräftige und sichere Analysen mit sensiblen Daten ermöglichen.
Sebastian Probst Eide ist CTO und Mitgründer von Aircloak. Nach seinem Informatikstudium an der Universität Cambridge arbeitete er mit Paul Francis, Direktor vom Max-Planck-Institut für Softwaresysteme und Felix Bauer an der Entwicklung von neuen Anonymisierungskonzepten. 2014 gründeten sie gemeinsam das Startup Aircloak. Mit der Lösung Aircloak Insights, die auf der neu entwickelten Anonymisierungsmethode Diffix basiert, möchten sie Unternehmen aussagekräftige und sichere Analysen mit sensiblen Daten ermöglichen.Moderne Forschung bietet eine neue Lösung
Neue Ansätze zur Anonymisierung können alle Dimensionen als potenziell identifizierend betrachten und erhalten dabei trotzdem eine hohe Datenqualität. Die Besonderheit liegt darin, dass die Anonymisierung nicht im Vornherein auf den kompletten Datensatz angewendet wird. Stattdessen werden nur die Dimensionen anonymisiert, die Teil der Abfrage sind – der Rest der Daten bleibt unberührt. Dieses Verfahren der “dynamischen Anonymisierung” gewährleistet eine starke Anonymität der Daten bei gleichzeitig sehr hoher Aussagefähigkeit.
Einziger Wermutstropfen: Während ein Data Scientist in der Vergangenheit mit einem einmalig anonymisierten Datensatz gearbeitet hat und an den Umgang mit einem solchen gewöhnt ist, muss er nun seine Arbeitsweise ändern und Queries innerhalb einer speziellen Anonymisierungs-Engine formulieren.”
In Anbetracht der Alternativen – nämlich die Daten gar nicht zu nutzen – ein, wie ich finde, sich lohnender Kompromiss.
Die derzeit zwei bekanntesten Methoden zur dynamischen Anonymisierung sind Differential Privacy und Diffix. Differential Privacy hat seinen Ursprung bei Microsoft Research und ist mittlerweile unter Forschern aufgrund seiner mathematischen Stringenz sehr beliebt. Diffix ist ein neuartiger Ansatz, der beim Max-Planck-Institut für Softwaresysteme als Alternative zu Differential Privacy entwickelt wurde. Im Vergleich lassen sich hiermit noch bessere Ergebnisse erzielen, da es eine freiere Arbeit mit einer größeren Anzahl an Daten erlaubt. Je nach Anwendungsfall kann eine statische oder dynamische Anonymisierung besser funktionieren – ich kann Ihnen daher nur empfehlen, die einzelnen Methoden genauer zu evaluieren.
Persönlich halte ich die Einführung der DSGVO für einen Meilenstein. Unsere Daten mussten noch nie so sehr geschützt werden, wie heute – allerdings erfordert das auch einen sorgfältigeren Umgang mit sensiblen Informationen. Anonymisierung kann einen großen Anteil dazu beitragen und die Arbeit mit Daten wesentlich erleichtern.aj
Sie finden diesen Artikel im Internet auf der Website:
https://itfm.link/73373


Schreiben Sie einen Kommentar