

Werden (Kunden-)Daten in Banking-Chatbots nun sicher(er)? Differential Privacy-Ansatz gegen Datenleaks

Grok
Es war ein Gau: In ChatGPT wurden am 20. März 2023 die Chat-Verläufe fremder Personen angezeigt. Italien reagierte und sperrte ChatGPT noch im selben Monat – negative Publicity und Vertrauensverluste für OpenAI inklusive. Ganz zu schweigen von den Folgen für Betroffene.
Der Vorfall veranschaulicht Entwicklern: Die Gewährleistung der Sicherheit von (personenbezogenen und sensiblen) Nutzerdaten ist unabdingbar und es muss ein „Spagat“ zur „datenhamsternden“ NLP-Technologie gemeistert werden.
Differential Privacy überzeugt im Experiment
Im Oktober 2024 veröffentlichten nun sechs Forscher aus den USA und China ein Paper, in dem Differential Privacy vorgestellt wird. Der praktikable Datenschutzansatz überzeugt im Experiment der Forscher.
Rund 17 Forschungsansätze über Datenschutzoptimierung von NLP-Systemen werden aufgeführt. Differential Privacy sticht u. a. hervor, indem es die Modellleistung nur gering bis moderat beeinträchtigt (je nach Datenschutzerfordernis). Ziel von Differential Privacy ist: maximaler Datenschutz bei möglichst gleichbleibender (Modell-)Leistung.

Studie: Balancing Innovation and Privacy
Funktionsweise von Differential Privacy
Die Idee: Im Trainingsprozess (eines NLP-Modells) werden mit zufälligem (gaußschem) Rauschen spezifische Informationen aus (Trainings-)Datensätzen „verschleiert“.
 Eric Funke ist freier Fachjournalist, der sich auf den IT-Finanzbereich spezialisiert hat. Vor seiner freiberuflichen Tätigkeit arbeitete er bei der UniCredit Bank und verfasste dort ein Handbuch..
Eric Funke ist freier Fachjournalist, der sich auf den IT-Finanzbereich spezialisiert hat. Vor seiner freiberuflichen Tätigkeit arbeitete er bei der UniCredit Bank und verfasste dort ein Handbuch..Vergleich von fünf „Privatsphäremodellen“
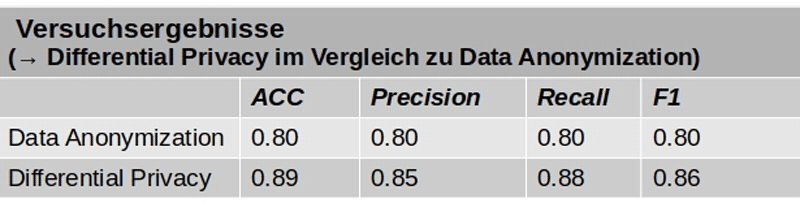
In dem Paper wird ein Experiment aufgeführt, dass fünf Ansätze miteinander vergleicht. In allen Scores (ACC, Precision, Recall, F1) übertrumpfte Differential Privacy folgende „Vergleichsmodelle“:
1. Data Anonymization,2. Homomorphic Encryption,
3. Secure Multi-Party Computing,
4. Federated Learning.
Insbesondere gegenüber Data Anonymization hebt sich Differential Privacy ab:
Studie: Balancing Innovation and Privacy
Schlussbetrachtung:
Die Studie (PDF hier) Paper trifft den Zeitgeist. In der Finanzbranche sorgten jüngst die EU-Datenschutzgrundverordnung (EU-DSGVO) und andere relevante Vorschriften für signifikant höhere Datenschutzanforderungen. Insbesondere wird dabei gefordert: mehr Transparenz und Kontrolle für die Nutzer.
Differential Privacy scheint laut Experiment geeignet, um dem zu begegnen. Insbesondere in Kombination mit anderen Methoden. Der Ansatz zeichnet sich aus durch Flexibilität und geringe(re) Modellbeeinträchtigung. Regulatorische Vorschriften und der negative Marketingeffekt bei Datenschutzversagen erfordern m. E. den Datenschutz in NLP in der Chatbot-Entwicklung zu einem „Kernpfeiler“ zu forcieren.Eric Funke, Fachjournalist
Literaturverzeichnis:
Studie: https://arxiv.org/pdf/2410.08553
Sie finden diesen Artikel im Internet auf der Website:
https://itfm.link/220803


Schreiben Sie einen Kommentar