Banken unterschätzen die Komplexität und den Umfang von Datenmigration und Datenintegrationsprojekten
Axel Schmale, Account Manager DQ Sales bei UniservUniserv
Marktkonsolidierung: Die comdirect ging in der FinTech-Studie 2017 davon aus, dass knapp drei Viertel der derzeitigen FinTechs im Jahr 2025 nicht mehr am Markt aktiv sein und auch eine Vielzahl an kleineren Banken aus dem Markt gedrängt haben werden. An- und Zukäufe, Übernahmen und Fusionen sind an der Tagesordnung. Und damit auch System- und Datenmigration – sowohl für die IT als auch für das Prozessmanagement. Aus der Praxis
von Axel Schmale, Account Manager Uniserv
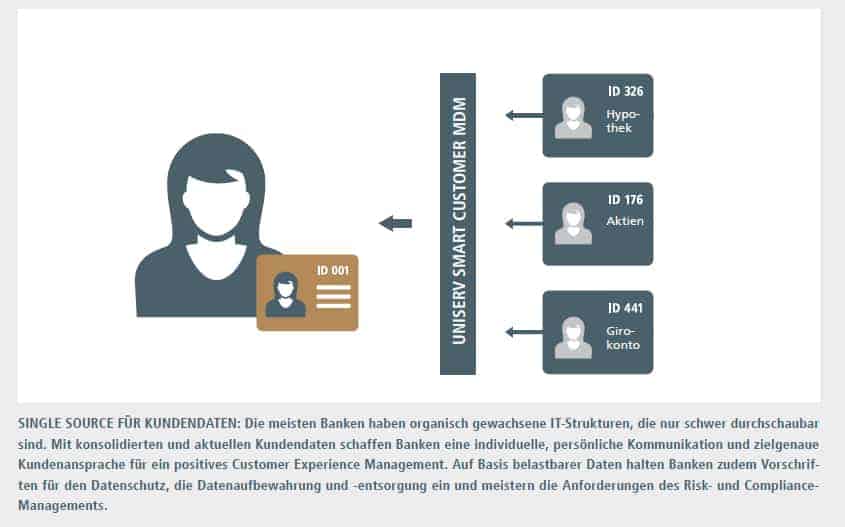
Dass die meisten Banken über organisch gewachsene IT-Strukturen verfügen, die nur schwer durchschaubar sind, ist ein alter Hut.
Im Einsatz sind immer noch Legacy-Systeme und ein Mix aus Kernbankensystemen, SAP-Lösungen oder Eigenentwicklungen.”
Uniserv
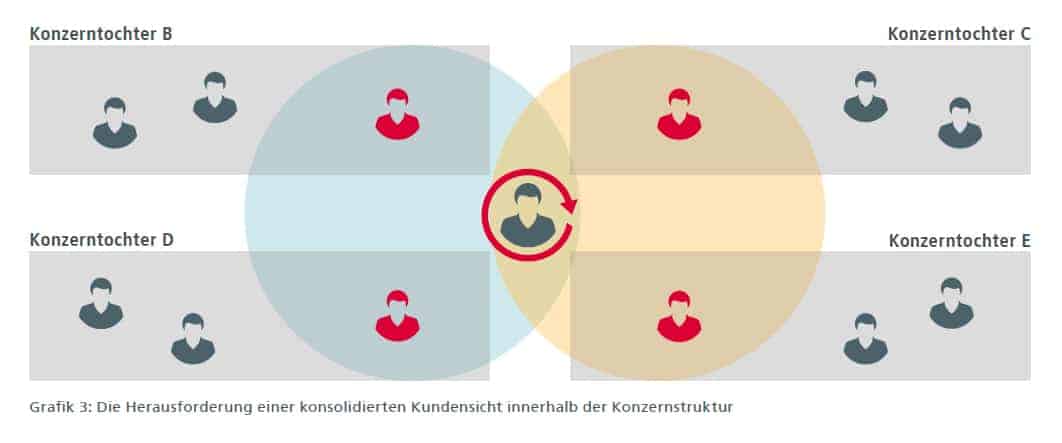
Bei Konzernstrukturen mit verschiedenen Tochtergesellschaften und Geschäftsbereichen kommen weitere unterschiedliche, voneinander isoliert betriebene IT-Systeme und Applikationen hinzu. Diese sind oft nicht in einer konzernübergreifenden IT-Plattform integriert. Sollen im Rahmen von Konsolidierungen und Fusionen nun Systeme und damit Daten von zwei oder mehreren Instituten oder Dependancen zusammengeführt werden, lauern Fallstricke. Aber auch wenn es gilt, steigende Regulations- und Reporting-Anforderungen zu erfüllen. Dann ist in einer heterogenen IT-Landschaft die Durchführung von Datenmigration oder zumindest Datenintegrationsprojekten oft der einzige Weg. So erfordern etwa Richtlinien wie DSGVO, PSD2 und BCBS 239 eine systemeinheitliche Sicht auf Daten – und dabei vor allem auf Kundendaten. Hierbei kann sich die Menge an Daten in Konzernunternehmen schnell mal auf 20 Millionen und mehr Datensätze summieren – mit unterschiedlichem Überschneidungsgrad je Kundengruppe oder Tochterunternehmen.
Vier Tipps zur Datenmigration
Tipps bei der Datenmigration: 1.Stakeholder einbinden, um die interne Akzeptanz des Projektes zu erhöhen: Mitarbeiter der Fachbereiche (Domain Experts), der IT, Data Owner, Data Stewards, Data Scientists sowie Experten des Zielsystems sollten im Datenmigrationsprojekt klare Rollen zugewiesen werden. 2.Revisionssicheres Reporting implementieren: Prüfen, ob möglicherweise eine unternehmens-/konzernweite Kunden-ID eingeführt werden sollte. So können Kunden und Geschäftspartner über Systemgrenzen hinweg eindeutig identifiziert werden, was Reporting und Sanktionslistenabgleich deutlich vereinfacht. 3.Quellsysteme reduzieren: Zu jedem Quellsystem einen Steckbrief anlegen, der die Daten, deren Verwendungszweck sowie die technischen Spezifikationen kurz beschreibt und den Namen des Data Owners enthält. Anschließend Bedingungen festlegen, nach denen Quellsysteme archiviert werden können. 4.Roll-Back-Strategie aufsetzen, um das Migrationsrisiko so gering wie möglich zu halten: Auch wenn die Migration noch so gründlich vorbereitet wird, können unvorhersehbare Umstände das Projekt gefährden. Entsprechende Strategien und Reprocessing-Abläufe senken das Risiko.
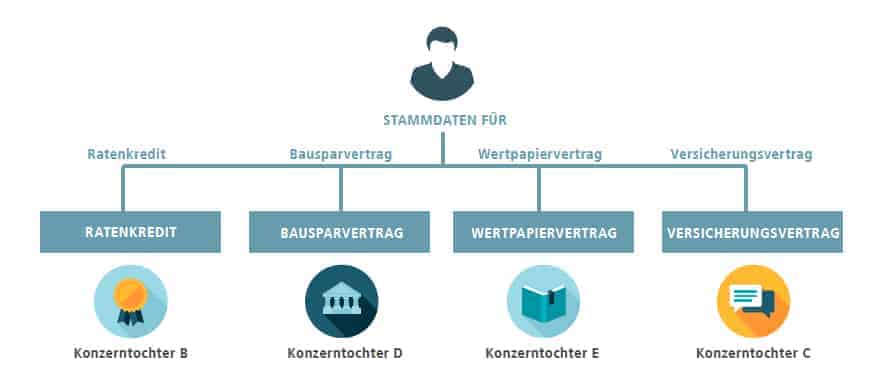
Die Kernfrage, die sich also in Vorbereitung von Datenintegrations- und Datenmigrations-Projekten stellt, ist daher: In welchen Systemen und Unternehmensbereichen liegen überhaupt geschäftsrelevante Kundendaten oder Geschäftspartnerdaten? Und das können viele sein. Denn einige Banken setzen je nach Produkt oder unterschiedlicher Produktlinie wie Bausparverträge, Kredit- und Versicherungsverträge oder Wertpapier- und Leasing-Produkte verschiedene IT-Applikationen ein. In jeder dieser Anwendungen finden sich wiederum sowohl verschiedene als auch redundante Informationen zum jeweiligen Geschäftspartner. Bei der Migration sollte es jedoch auf alle Fälle vermieden werden, doppelte oder mehrfach vorhandene Datensätze aus den Quellsystemen in das Zielsystem zu übernehmen. Laut Meinungsforschungsunternehmen Bloor Research treten bei mehr als 50 Prozent der Migrationsprojekte Kostenüberschreitungen und Verzögerungen auf. Oft ist die mangelnde Qualität der Daten die Ursache.
1. Data Cleansing: Quellsysteme vorbereiten
Nach einer entsprechenden Initialisierungs- und Konzeptphase sollte daher unbedingt der Status quo der Datenqualität in den Quellsystemen erhoben werden. Hierfür empfiehlt es sich, dass Projektverantwortliche zusammen mit den definierten Stakeholdern ein Datenqualitätsregelwerk für die betroffenen Geschäftsbereiche erstellen. Stakeholder können etwa Mitarbeiter der Fachbereiche (Domain Experts), der IT, Data Owner, Data Stewards sowie Experten des Zielsystems sein. Letztendlich soll auf diese Weise sichergestellt werden, dass nur diejenigen Daten ins Zielsystem migriert werden, deren Qualität den Anforderungen der jeweiligen Geschäftsbereiche entspricht.
Uniserv
Im anschließenden Data Cleansing genannten Schritt sollten die Daten einer postalischen Prüfung unterzogen, gegen offizielle Referenzdaten geprüft und gegebenenfalls korrigiert, Namenselemente vereinheitlicht und Dubletten identifiziert werden. Es ist empfehlenswert, die Suche nach potenziellen Dubletten zum einen innerhalb eines Systems durchzuführen – und zum anderen die verschiedenen Quellsysteme gegeneinander abzugleichen. Dieser Prozess kann automatisiert erfolgen. Dennoch sollten Projektverantwortliche darauf achten, hier eine fehlertolerante Lösung einzusetzen, die auch Dubletten erkennt, wenn die Schreibweise nicht zu 100 Prozent übereinstimmt. Außerdem sollte im Projekt ein Konsens über die Definition einer Dublette und den Umgang mit ihr getroffen werden. Denkbar kann eine teilweise automatisierte Bereinigung per Software für eindeutig identifizierte Dubletten sein. Für die manuelle Nachbearbeitung empfiehlt es sich, eine Clearing-Stelle einzurichten. Eine andere Möglichkeit ist das Festlegen eines führenden Datensatzes innerhalb der Dublettengruppe und das Setzen eines Löschkennzeichens für die Dubletten. Darüber hinaus können Daten in diesem Stadium auch mit externen Daten angereichert werden – etwa soziodemografische Daten oder geografische Informationen.
Im weiteren Projektverlauf erfolgt der Migrationsschritt. Spätestens hier muss feststehen, wie das Design des Zielsystems aussieht und welche Daten genau benötigt werden, um alle relevanten Informationen in das Zielsystem zu überführen. Somit wissen also alle Projektbeteiligten, welche Daten in welchem Format und zu welchem Zeitpunkt benötigt werden. Datenmodelle zeigen, aus welchen Quellsystemen die jeweiligen Daten zu übernehmen sind. Bei diesem Schritt sollten ebenso feldbasierte Transformationsregelwerke und Mappings erstellt werden. Diese enthalten genaue Anweisungen für die Datenumwandlung. Konkret geht es dabei um die Harmonisierung der Datenmodelle, Struktur-Mappings, Werte-Mappings und komplexe Transformationsregeln. Die heterogenen Datenmodelle aus Quell- und Zielsystem werden dann in einem einheitlichen Datenmodell zusammengeführt. In dieser Phase des Projekts sollten sich Verantwortliche unbedingt bewusst machen, dass Änderungen am Design des Zielsystems eine Vielzahl an Abhängigkeiten mit sich bringen. Dies kann zumindest zu einer zeitlichen Gefährdung des Migrationsprojekts führen.
3. Technische Migration: Build, Test, Go-Live
Anschließend erfolgt die eigentliche technische Migration. Bevor jedoch die finale Datenmigration geschieht, sollte in iterativen Testläufen geprüft werden, ob die Transformationsregeln so aufgesetzt sind, dass der Output den Anforderungen der Geschäftsbereiche entspricht. Eine fortwährende Beobachtung der Transformationsergebnisse durch Experten der betroffenen Geschäftssysteme ist daher unerlässlich. Testuser sollten die Daten prüfen, um Fehler so frühzeitig wie möglich zu entdeckt. Zum anderen muss das technische Szenario getestet werden, um auszuschließen, dass es zum Zeitpunkt der Migration zu vermeidbaren technischen Problemen kommt. Hier sollte immer das Motto gelten: „no late surprise“. Ist die Migration technisch umgesetzt und der Abnahmetest bestanden, kann die finale Datenmigration angestoßen und das Zielsystem produktiv genutzt werden. Ein Migrationsmonitoring sollte dabei die Übernahme der Daten vom Quellsystem ins Zielsystem überwachen. Anschließend können die Quellsysteme archiviert und aus der Produktivumgebung genommen werden.
Autor Axel Schmale, Uniserv
Axel Schmale ist Account Manager DQ Sales bei Uniserv und Branchenexperte für den Finanzsektor. Er hat über 15 Jahre Erfahrung in der IT-Branche. Für Uniserv begleitet Herr Schmale Banken und FinTechs auf dem Weg in die digitale Welt, mit besonderem Schwerpunkt auf dem Management von Kundendaten.
4. Nachhaltige Sicherung der Datenqualität
Diese Phase gehört zwar nicht mehr zum eigentlichen Migrationsprojekt, doch sollten Banken auch nach der Migration darauf achten, dass künftig nur qualitativ hochwertige Daten in das Zielsystem aufgenommen werden (First Time Right). Zur Überwachung der Datenqualität kann beispielsweise ein Monitoring implementiert werden. Es empfiehlt sich, die Monitoringregeln an das Datenqualitätsregelwerks (Data Cleansing), das im Vorfeld der Migration festgelegt wurde, anzupassen. Im Fall einer qualitativen Verschlechterung können Projektverantwortliche dann zeitnah Maßnahmen ergreifen, die die Datenqualität wieder auf das erforderliche Niveau bringen. Zudem ist gerade in Kreditinstituten eine fortlaufend hohe Datenqualität notwendig, wenn es beispielsweise um Betrugsabwehr geht – und um Sanktionslistenprüfung, etwa nach dem KYC-Prinzip. Vor allem bei Bankenfusionen sollten Verantwortliche die externen Datenbestände, die in das bestehende System integriert werden müssen oder dazu dienen, eigene Daten anzureichern, vor der Migration in den Datenbestand hinsichtlich der gesetzlichen Auflagen überprüfen. Werden aufgrund schlechter Datenbestände etwa PEPs nicht erkannt, drohen Bußgelder und Sanktionsmaßnahmen.
Uniserv
Datenmigration: Das Fazit
Stimmt die Datenbasis nicht, ist die Wahrscheinlichkeit hoch, dass Datenmigration und Datenintegrations-Projekte scheitern. Darüber hinaus sind gesetzlich vorgeschriebene Reportings nicht belastbar, Betrugsabwehrmechanismen können nicht greifen und Compliance-Anforderungen nicht eingehalten werden. Banken sollten der Qualitätssicherung also nicht nur während des Migrationsprojekts, sondern auch danach entsprechend hohe Aufmerksamkeit schenken – und das konzernübergreifend über alle Tochterunternehmen und Einheiten hinweg.aj
Sie finden diesen Artikel im Internet auf der Website: https://itfm.link/77001



 Axel Schmale ist Account Manager DQ Sales bei Uniserv und Branchenexperte für den Finanzsektor. Er hat über 15 Jahre Erfahrung in der IT-Branche. Für Uniserv begleitet Herr Schmale Banken und FinTechs auf dem Weg in die digitale Welt, mit besonderem Schwerpunkt auf dem Management von Kundendaten.
Axel Schmale ist Account Manager DQ Sales bei Uniserv und Branchenexperte für den Finanzsektor. Er hat über 15 Jahre Erfahrung in der IT-Branche. Für Uniserv begleitet Herr Schmale Banken und FinTechs auf dem Weg in die digitale Welt, mit besonderem Schwerpunkt auf dem Management von Kundendaten.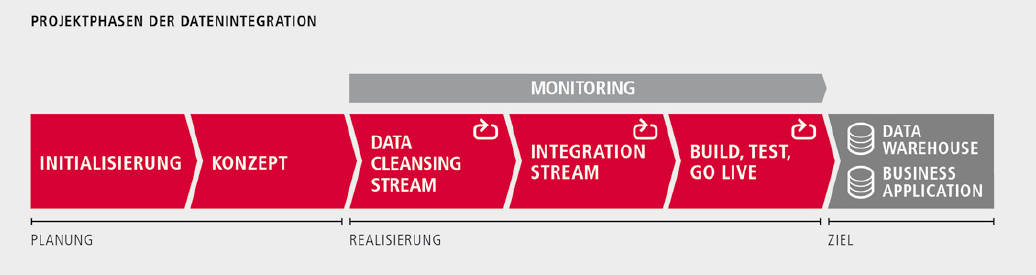


Schreiben Sie einen Kommentar